### Classes
:Agent a owl:Class . # aligns with prov:Agent, crm:E21
:Work a owl:Class . # aligns with mo:MusicalWork, dct:BibliographicResource
:Role a owl:Class . # internal role concept
### Properties
:hasRole a owl:ObjectProperty .
:roleOf a owl:ObjectProperty ; owl:inverseOf :hasRole .
:roleType a owl:DatatypeProperty .
### Instances
:Work123 a :Work .
:Person456 a :Agent .
:Contribution789 a :Role ;
:roleType "composer" ;
prov:wasAssociatedWith :Person456 ;
dct:subject :Work123 .5 Data coordination
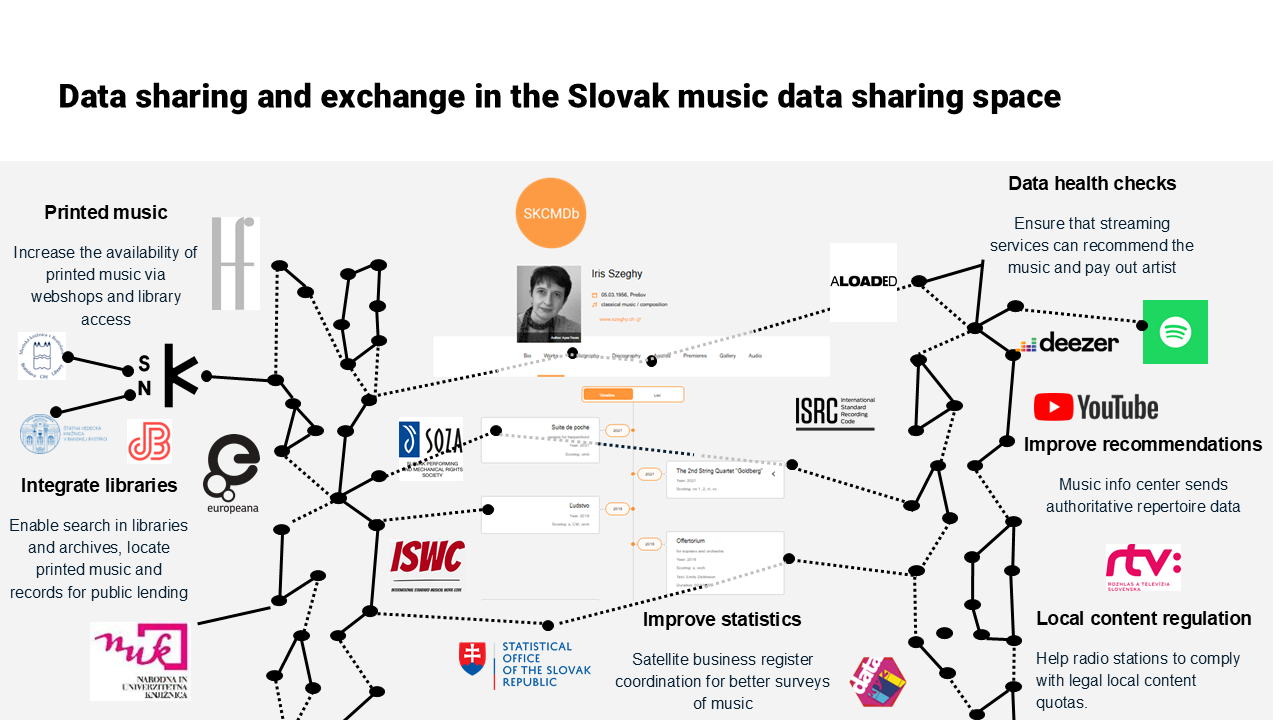
Cultural and music data in Europe is generated and maintained by a highly diverse set of organisations. National libraries, archives, museums, collective rights management organisations, academic research projects, streaming platforms, local cultural associations, and commercial distributors all describe the same creators, the same works, and the same recordings—but they do so for different purposes, using different conceptual models, and under different legal and organisational constraints. These systems have grown organically over decades, reflecting local traditions, professional cultures, and technical possibilities. As a result, the same piece of music may be catalogued differently in an archive, credited differently in a rights database, indexed differently in a library catalogue, and published differently on a digital music service. This fragmentation reflects the structure of the music ecosystem itself, which is distributed across creators, labels, publishers, collective management organisations, distributors, archives, and digital platforms that each maintain their own data infrastructures.
This fragmentation was already identified in the Feasibility Study for a European Music Observatory, which noted that music-sector metadata is “structurally scattered across private and public registers that seldom interconnect” (European Commission et al. 2020, 9–10). The Study explicitly highlighted the absence of a “functional link between ISWC, ISRC, ISNI and VIAF” as a core obstacle to evidence-building [p. 46–48]. The CITF First Project Report reaches the same conclusion in the textual domain, observing that rights metadata lacks “cross-registry alignment, lifecycle-based provenance, and interoperable identifiers” [Partanen et al. (2025), p. 20–22; p. 31]. These findings reinforce the need for a coordination model that can operate across independent registers without replacing them—precisely the purpose of a data sharing space. In practice, this means building infrastructures that allow heterogeneous registries and catalogues to interoperate through shared identifiers, alignment patterns, and workflow coordination rather than through centralisation.
This fragmentation is not a sign of failure; it is the natural consequence of cultural stewardship being distributed across many institutions with distinct missions. However, fragmentation becomes a problem when people attempt to connect, reuse, or reinterpret information across domains. Without coordination, data cannot be trusted across systems: names do not match; contributor roles are incompatible; identifiers are missing or ambiguous; and important aspects of minority or community-based cultural heritage may be lost or become invisible.
The need for coordination arises from this structural diversity. Institutions should not be forced to adopt a single metadata standard or a single software system, but they must be able to communicate meaningfully. Coordination provides the minimum shared semantic and technical foundations that enable such communication. Coordination also supports equity and cultural diversity. By lowering the technical threshold for participation, coordinated infrastructures allow smaller institutions and community collections to contribute data that would otherwise remain disconnected from European research and cultural infrastructures. Smaller institutions—community archives, ethnographic collections, minority cultural groups, and local music organisations—often lack the resources to operate modern digital infrastructures. Without coordinated frameworks, their data cannot easily participate in larger European infrastructures or data spaces, which in turn reinforces cultural imbalances.
Coordination therefore serves not only technical efficiency but also cultural policy objectives related to inclusion, multilingualism, regional diversity, and the representation of endangered traditions.
The European Parliament’s Resolution on Cultural Diversity and the Conditions for Authors in the European Music Streaming Market makes this a policy priority, stressing that fair remuneration and discoverability depend on “comprehensive and accurate allocation of metadata from the time of creation” and on adoption of all international identifiers (IPI, ISWC, ISRC, ISNI, IPN) (European Parliament 2024, recital 32). The EU Music Ecosystem Study similarly notes that fragmentation in metadata and identifier systems “prevents cross-border comparability and weakens the evidence base for policy” (Music Moves Europe 2024, 42–45). Coordination is therefore a legal and policy requirement, not simply a technical improvement. Implementing such coordination requires infrastructures that translate policy requirements—such as accurate metadata allocation, identifier adoption, and cross-registry alignment—into operational workflows that institutions can actually maintain.
5.0.1 The European Interoperability Framework (EIF)
The European Interoperability Framework (EIF) provides guidance for how heterogeneous public-sector systems can work together without sacrificing their autonomy. It identifies four layers of interoperability—legal, organisational, semantic, and technical—and emphasises that meaningful interoperability requires all four to be addressed1.
The EIF provides the most relevant cross-sectoral guidance for this problem. The European Interoperability Framework Implementation Strategy stresses that interoperability must balance institutional autonomy with cross-sector alignment, and that semantic mediation—not schema unification—is the correct method for heterogeneous domains (European Commission 2017b, 9–14). This perspective is echoed in the Data Spaces Support Centre Blueprint v2.0, which states that common European data spaces must provide “shared semantics, identifier resolution, and rulebooks for interoperability” rather than imposing a single ontology (Data Spaces Support Centre 2025, 35–39).
The EIF’s underlying philosophy is that institutions will always differ in their practices, constraints, and goals. Therefore, interoperability cannot be achieved by imposing uniformity. Instead, it must enable institutions to maintain their internal systems while still participating in a shared ecosystem.
Although the EIF was not developed specifically for the cultural or music domains, but generally to public digital services, its principles apply directly, because most music services are digital, and they are often public in nature, too.
Cultural data infrastructures face the same challenges the EIF describes:
different legislation (e.g., copyright, orphan works, deposit laws),
different organisational workflows (cataloguing, digitisation, rights clearance),
and different semantic traditions (archival provenance, library authority control, rights metadata, music industry credits).
The EIF also emphasises reusability, transparency, and proportionality—all central issues for cultural data governance, particularly when dealing with sensitive material, intangible heritage, and community-generated knowledge. Most importantly, the EIF recognises that interoperability is not a technical property alone.
It is a sociotechnical negotiation across institutions, requiring trust, shared agreements, and mechanisms for maintaining alignment over time. This recognition makes the EIF a strong conceptual foundation for coordinating cultural and music data, even when many actors fall outside the classical public-sector domain.
In the cultural and creative sectors, this perspective aligns with the work of the Copyright Infrastructure Task Force (CITF), which analyses how copyright infrastructures depend on interoperable identifiers, metadata schemas, and machine-readable rights information. The CITF work builds on the EU study on copyright infrastructure and therefore concentrates primarily on the semantic and technical layers of interoperability that allow rights metadata to circulate across registries and systems.
The Open Music Observatory complements this perspective by adopting the broader framework of the EIF. While CITF focuses on semantic interoperability, the EIF also addresses organisational and legal interoperability — the institutional cooperation, governance arrangements, contractual frameworks, and operational workflows that allow infrastructures to function in practice. In this sense, the Observatory translates the lifecycle processes and operational requirements identified by CITF into concrete digital business processes and coordination mechanisms between creators, rights organisations, cultural heritage institutions, distributors, and digital platforms.
5.0.2 Extending the EIF to public and private service coordination
Cultural data ecosystems are unique because they span both public and private infrastructures.
A library’s bibliographic record for a musical work interacts with rights information managed by collective management organisations, which in turn interacts with ISWC and ISRC registries maintained by industry actors.
A museum’s digitised ethnographic collection may be reused by researchers, by minority communities seeking cultural revival, or by streaming services presenting curated heritage playlists. Public institutions depend on commercial metadata pipelines for up-to-date identifiers, contributor roles, and distribution metadata; commercial actors depend on public institutions for authoritative information, contextual enrichment, and long-term preservation.
To coordinate across this mixed ecosystem, the EIF must be extended beyond its original scope.
This extension is explicitly anticipated in the EU’s data governance framework. The Data Governance Act requires that cross-sector reuse of protected data be mediated through shared governance mechanisms and semantic alignment [Regulation (EU) 2022/868, Art. 8–12]. The Data Act reinforces that business-to-government and business-to-business reuse must rely on interoperable identifiers and machine-readable formats [Regulation (EU) 2023/2854, Art. 3–4]. The CITF report further argues that trustworthy AI requires alignment across private registries (publishers, collecting societies) and public infrastructures (national libraries, VIAF, ISNI), because “lifecycle-level provenance cannot be ensured in siloed systems” (Partanen et al. 2025, 101–2).
Public–private coordination requires shared semantics, shared identifiers, and shared rules for linking, even when underlying workflows remain distinct. For example, DDEX roles must be interpretable by library and archival systems, just as archival provenance must be interpretable by music distributors when republishing historical recordings. Similarly, community-generated metadata (such as language revitalisation initiatives or fieldwork collections) must be able to participate in rights and distribution pipelines without being forced into commercial templates that erase cultural meaning.
Extending the EIF in this way does not imply that private systems become part of public digital government infrastructures. It means that coordination mechanisms—identifier mapping, semantic mediation, minimal ontological alignment, provenance tracking, rights documentation—must operate across both sectors. This allows public and private services to interoperate responsibly while preserving their organisational autonomy and legal boundaries. The result is a more inclusive, resilient ecosystem, where cultural data can move across domains without losing meaning or trustworthiness.
5.0.3 Data sharing space
A data sharing space is a distributed, federated infrastructure in which institutions agree on a minimal set of rules for linking and interpreting each other’s data.
The concept of a data sharing space is directly aligned with the Design Principles for Data Spaces published by the International Data Spaces Association and adopted by the European Commission. Data spaces are defined as “federated data ecosystems within a specific domain, operating on shared semantics, trust frameworks, and rulebooks” rather than as central repositories (Nagel and Lycklama 2021, 7–9). The CEEMID initiative anticipated many of these principles a decade earlier by demonstrating that decentralised linking—rather than centralisation—is the only viable model for cultural and creative sector data (Antal 2020, 18–22).
Unlike a centralised database, a data sharing space does not require institutions to upload all their data into a single platform or adopt a single schema. Instead, it provides a semantic mediation layer—shared identifiers, alignment patterns, equivalence mappings, and reference ontologies—that allows heterogeneous systems to interoperate.
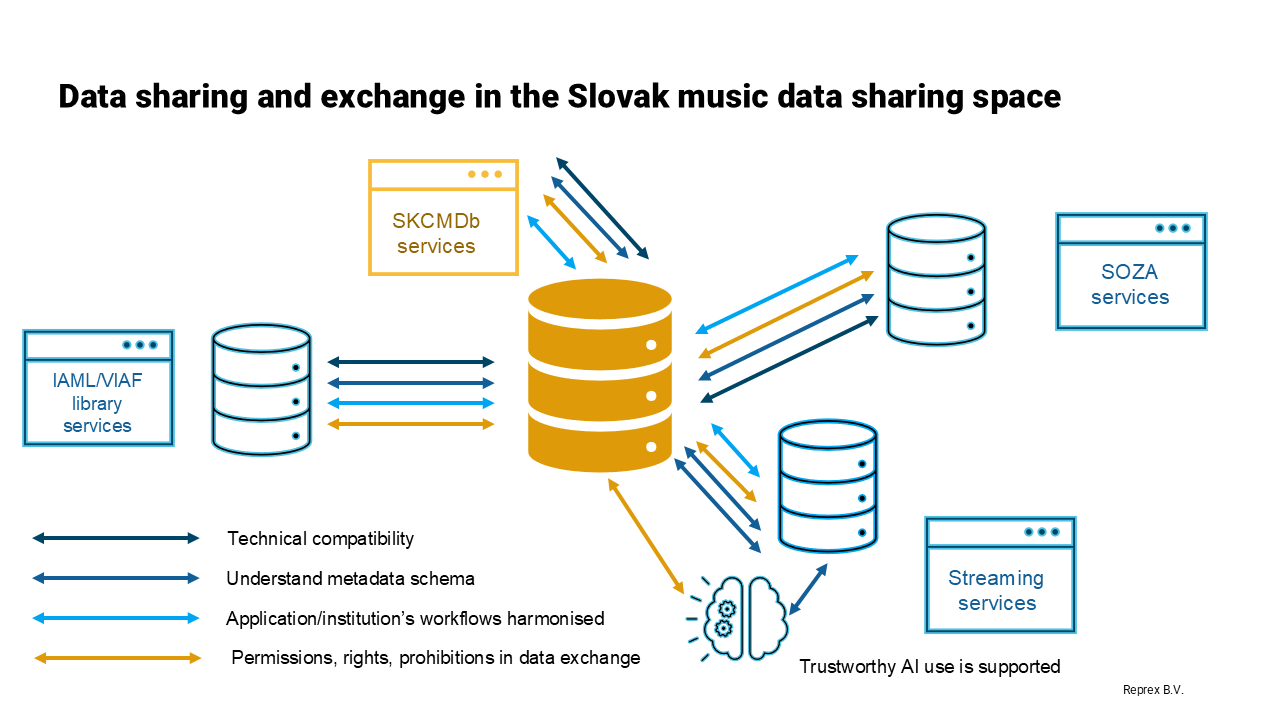
Data sharing spaces are particularly suitable for cultural and music ecosystems, where no single actor can control the entire landscape. They allow archives to link to music distributors, libraries to link to rights registries, and community collections to link to research datasets, without forcing any of these institutions to abandon their internal models.
A data sharing space can support service integration in practical, operational ways. For example, archival metadata describing a traditional song can be transformed into DDEX metadata for legal distribution; a library’s authority record can enrich a rights organisation’s contributor database; a researcher’s MIR dataset can link to digitised collections; and a community can add linguistically and culturally meaningful information without overwriting institutional records.
Because data sharing spaces respect institutional autonomy, they can grow incrementally. Institutions can join at different levels of readiness, linking only what they are comfortable sharing. Over time, shared identifiers and alignment patterns accumulate, improving the quality and connectivity of the ecosystem as a whole.
The data sharing space becomes the place where coordinated services emerge: discovery interfaces spanning multiple institutions, rights-aware access systems, cross-domain research environments, and community-led enrichment workflows. In this way, a data sharing space serves as the structural foundation for a coordinated, equitable, and future-proof European cultural and music data infrastructure.
5.1 Ontologies and Vocabularies in the Open Music Observatory
The Open Music Observatory (OMO) does not aim to create new ontologies.
Instead, it integrates and reuses existing, well-established data models from the open data and cultural heritage ecosystems.
In practice, this means that our data spaces and pilot projects (e.g. SKCMDb, Finno-Ugric Data Space, TextileBase) combine metadata drawn from:
- Open Government and Open Science:
DCAT-AP — the European data portal metadata model. - Cultural Heritage and GLAM:
EDM (Europeana Data Model),
CIDOC CRM, and Records in Contexts (RiC). - Emerging Cultural Infrastructure:
High-Definition & Collaborative Cultural Data Infrastructure (HDTO). - Common Metadata Principles:
Dublin Core Terms (DCTERMS) — for general metadata interoperability.
- Music Industry Standards:
ISWC for works,
ISRC for recordings,
DDEX for metadata exchange and release categorisation.
Our goal is not to add another layer of complexity, but to connect these existing models so that cultural heritage data, rights management systems, and research metadata can interoperate seamlessly.
This bridging strategy mirrors the approach taken in cultural heritage infrastructures such as Europeana (EDM), the emerging Heritage Digital Twin Ontology (HDTO), and the EOSC semantic interoperability guidelines, all of which rely on equivalence mappings and lightweight ontology design patterns rather than top-down schema replacement (ECHOES Ontology Task Force 2025, 5–7; 2020 2020, 13–19). This is the same approach recommended by the CITF report for cross-registry rights metadata (Partanen et al. 2025, 31).
NoteOpen Music Observatory Ontology Approach
The Observatory uses a Wikibase-based ontology layer, derived from the Wikibase Ontology.
This defines classes and properties that are compatible with the Wikidata ecosystem.Equivalence links (
owl:equivalentClass,owl:equivalentProperty) are added to map our entities to reference ontologies such as:dcterms:(Dublin Core)rico:(Records in Contexts)crm:(CIDOC CRM)edm:(Europeana Data Model)dcat:(DCAT-AP)- and others used in European data spaces.
For industry standards (like ISWC, ISRC, and DDEX) that are not published in formal RDF/OWL form, the Observatory provides a minimal ontological scaffolding under the
Open Music Ontology (omo)namespace. The source files of this minimal ontology are held at https://github.com/dataobservatory-eu/open-muisc-ontology
This ensures that:
industry identifiers can be represented and queried alongside heritage data,
and semantic equivalence can be maintained across research, rights, and cultural collections.
In short, OMO acts as a semantic bridge, not as a new ontology.
In summary: The Open Music Observatory’s semantic stack connects ontologies — it doesn’t reinvent them. It provides a thin, open, interoperable layer across public, research, and industry vocabularies to keep European music data FAIR and reusable.
In several crucial domains — particularly DDEX release modelling, contributor roles, and industry identifiers — no official ontological form exists, even though these standards make clear ontological commitments. As part of the Open Music Observatory’s coordination workflow, we therefore export these commitments into machine-readable, future-proof RDF/OWL form, ensuring that concepts defined only in prose or PDFs can participate in a data sharing space. This work is carried out in the Open Music Ontology (OMO), a minimal bridging vocabulary that expresses the semantics of key industry terms (e.g. ISWC, ISRC, release types, contributor roles) without redefining or replacing the authoritative standards. OMO provides neutral, interoperable helper classes and properties — such as omo:Recording, omo:MusicalWork, omo:ReleaseCategory, omo:hasISRC, and omo:hasContributorRole — that allow DDEX-aligned metadata to coexist with GLAM, research, and open-data vocabularies. This ensures that industry metadata can be queried alongside cultural heritage data, and that future systems can rely on stable RDF/OWL definitions rather than informal textual descriptions (Antal 2025c).
In a data sharing space, the shared “data model” cannot be a single unified ontology. Instead, a DSS must implement a semantic mediation layer capable of interpreting and mapping heterogeneous, co-existing conceptual models.
This is consistent with the Data Space Blueprint, the European Interoperability Framework (EIF), and Gaia-X design principles, all of which explicitly require semantic interoperability rather than schema unification.
Our approach implements this through a Wikibase-based mapping layer using:
– equivalence relations (owl:sameAs / near-equivalents), – pattern-based re-expression of relationships, and – lightweight ontological fragments (ontology design patterns).
This allows the data space to reuse established ontologies (CIDOC CRM, DCTERMS, RiC-O, DDEX, Music Ontology, Polifonia ODPs) while avoiding ontology hijacking and respecting the epistemic structures of domain-specific data (e.g., music, Finno-Ugric heritage).
Technically, this produces a federated semantic layer, not a single global schema — exactly the architecture envisaged by BDVA and Gaia-X for cross-domain data spaces.
5.1.1 Lightweight Ontology Patterns
We emphasize modular ontological patterns over rigid global alignment with identifying reusable semantic fragments.
:Work123 wdt:P86 :Person456 . # "composer" (WM property)
# But we want *more semantic detail*, so we reify:
:Work123 p:P86 _:stmt1 .
_:stmt1 ps:P86 :Person456 ;
pq:P453 :RoleComposer ; # fake property: role type
prov:wasDerivedFrom :SourceXYZ .Where:
P86= “composer”P453= “role type” (made-up but plausible)provenance is given by
prov:wasDerivedFrom
This fragment is lightweight but powerful because:
- It does not force the import of full CIDOC-CRM / MO / PROV fully; which would invite contradictions among models designed for different use cases.
5.2 Multiple roles, multiple workflows to support
The need to model multiple contributions per person does not arise only from semantic complexity; it arises equally from the organisational complexity of the music and cultural heritage ecosystem. The European Interoperability Framework (EIF) makes this explicit. It emphasises that interoperability is not merely a matter of exchanging data, but of aligning legal, organisational, semantic, and technical layers so that institutions with different mandates can actually work together in practice.
In our domain, these organisational differences are profound. A single music professional—a composer, lyricist, performer, teacher, field collector, journalist, or scholar—appears in the workflows of multiple institutions, each operating under different constraints, professional cultures, and data traditions.
Rights managers (CMOs) track authorship, contractual shares, mandated roles, local membership, and payment obligations; their systems are built around ISWC, ISRC, DDEX message flows, and national royalty rules.
Libraries describe publications, field notes, monographs, pamphlets, or educational material created by the same person, expressed via DCTERMS, MARC, and authority files such as VIAF or national bibliographies.
Archives preserve and describe primary research and documentation—field recordings, notebooks, interviews—using Records in Contexts (RiC-O) or legacy finding aids, with an emphasis on provenance rather than artistic authorship.
Music distributors and digital platforms focus on releases, rights clearance, credits, platform metadata, and consumption metrics—very different operational purposes again.
All these perspectives refer to the same individuals, yet each institution’s workflow interprets the person differently. For a rights manager, the same person is primarily a rights holder or contractual party; for a library, an author or editor; for an archive, a creator of records or a subject of description; for a music service, a performing artist or contributor. These classifications are valid within their organisational contexts, but not easily reconciled into a single conceptual model.
This is where the organisational layer of the EIF becomes essential. It recognises that organisations have different goals, responsibilities, mandates, and lifecycle workflows for working with the same entities. Because these workflows are not uniform, the underlying data models cannot be forced into uniformity either. To do so would impose one organisation’s worldview onto another, which the EIF explicitly warns against.
Therefore, in a data sharing space we deliberately avoid semantic conformity and instead pursue semantic interoperability:
we do not require a single ontology;
we do not impose unified classes or roles on all participants;
and we do not collapse diverse workflows into one abstract conceptualisation.
Instead, the data sharing space provides a semantic mediation layer that allows, for example, a rights-management IT system and a library application—or an archival suite and a music distribution platform—to interoperate even though their internal conceptualisations are incompatible.
This is precisely why we adopt modular, pattern-based representations of roles and contributions. They allow a single person to have any number of contributions across institutional contexts without forcing libraries to adopt rights-management vocabulary, without forcing archives to adopt music ontologies, and without requiring commercial metadata pipelines to express provenance in the style of libraries or museums.
In other words:
the data sharing space preserves organisational autonomy while enabling semantic connections.
The goal of the data sharing space is not data exchange for its own sake. The goal is to let heterogeneous systems work together across the lifecycles of cultural material, even when they treat the same agents and works very differently. Librarians, archivists, rights managers, ethnographers, cultural researchers, and music distributors all produce and need information about the same individuals—but they do so for different purposes, at different times, under different constraints, and using different data models.
The data sharing space respects these differences rather than erasing them. Its contribution is to connect, not homogenise. By allowing a person to accumulate multiple, context-specific contributions—and by permitting these contributions to be classified differently in different organisational settings—the DSS creates an interoperative ecosystem without imposing a universal conceptual schema.
This approach is completely aligned with the EIF:
Legal interoperability: each institution retains its own rights and contractual frameworks.
Organisational interoperability: each institution keeps its workflow and functional logic.
Semantic interoperability: meanings can be mapped without requiring conformity.
Technical interoperability: the systems exchange identifiers, links, and reference patterns.
This is why a data sharing space succeeds where unified ontology engineering fails. It supports real institutional work, not an abstract harmonisation of concepts, enabling rights management systems, library catalogues, archival suites, and music distribution platforms to collaborate while remaining true to their respective missions.
5.2.1 Polyhierarchy
The issue of polyhierarchy is not a minor edge case: it is at the heart of why large-scale, multi-domain knowledge graphs—such as Wikidata, or our own data sharing spaces—struggle with representing cultural and musical reality accurately. In the Wikidata Ontology Cleanup Task Force and the Mereology Task Force, that the data professionals of the Open Music Observatory joined, we encounter the same structural tension: different communities use the “part of” relation in incompatible ways because they operate in different hierarchical systems that reflect different organisational needs.
Wikidata currently contains probably over a hundred implicit or near-equivalent uses of the “part of” relation. Sometimes “part of” expresses a physical mereology (a page as part of a book), sometimes a conceptual hierarchy (a movement as part of a symphony), sometimes an organisational grouping (a track as part of an album), sometimes a legal–economic relationship (a track being part of a rights bundle), and sometimes an abstract knowledge-organisation hierarchy (a concept being part of a broader field). These are not equivalent uses, and attempting to force them into a single hierarchy or a strict ontology rapidly leads to contradictions.
This is not a flaw in Wikidata—it is an unavoidable consequence of operating a general-purpose ontology used simultaneously by librarians, rights managers, musicologists, archivists, biologists, pharmaceutical researchers, geographers, and cultural heritage professionals. Each of these communities inherits its own modelling tradition. And crucially, those traditions reflect organisational workflows, not just semantic preferences.
For example, in music: - A library catalogue does not care that a CD contains ten tracks composed by different authors; it treats the CD as a loanable unit. - A rights manager cares deeply about track-level authorship because royalties and licensing depend on it. - A musicologist may care about movements and sub-movements within a single work. - A digital distributor (DDEX) distinguishes between recordings, sound files, releases, and release bundles in ways foreign to both librarians and archivists.
No single hierarchy can serve all of these purposes simultaneously.
This is precisely the problem that the archival world has grappled with for decades. In traditional archival theory, the “unit of description” could be: a fonds, a series, box, folder in a fonds, a file, a letter or even a page of the letter.
This is not a matter of ontological taste; it is an organisational reality shaped by the scale of collections, staff capacity, digitisation status, and cataloguing philosophy. Archives did not fail to formalise these differences because they lacked ontologists—they struggled because hierarchy itself is variable, contextual, and meaningful.
In our efforts to create a pragmatic model for the Open Music Observatory we were informed and influenced by the outcomes of the ten-year effort to produce the Records in Contexts Conceptual Model (RiC-CM). RiC is essentially an attempt to design an ontology that could tolerate hierarchical variability between a deep archival system of a well-staffed national archive and a small community archive. RiC does not eliminate polyhierarchy; instead, it tries to provide a flexible, graph-oriented language for representing multiple hierarchical and non-hierarchical relationships at once. The result is powerful but also demanding. It is telling that, despite the conceptual elegance of RiC, few archives have rushed to replace ISAD(G). The conceptual shift is too large, the costs too high, and the implications for organisational workflow too complex. Music archive designers will have to support ISAD(G) and RiC for decades to come. (Needless to say, the designers of RiC were fully aware of this and the gradual transition is possibly.)
Similarly, libraries never truly adopted FRBRoo, even though it theoretically offered a perfect hierarchy of Work → Expression → Manifestation → Item. Why? Because libraries operate under real organisational constraints, like existing cataloguing practices, legacy IT systems, patron-facing interfaces that users are loyal too, acquisition workflows, physical holdings and their storage,loan systems. FRBRoo’s clean theoretical hierarchy simply does not map onto the messy, practical realities of the often underfunded realities of a smaller music library’s operations.
This is exactly the lesson that Wikidata, and any data sharing space, must internalise: polyhierarchy is not a modelling flaw—it is a reflection of institutional diversity. Different institutions use different hierarchies not because they disagree, but because they serve different roles. A “part of” relation means something different in a conservation lab, a collective rights management organisation, a radio station’s playlist editor, a digitisation workflow, or an archival fonds description.
The challenge is not to normalise all of these viewpoints into a single hierarchy. The challenge is to create a modelling environment where multiple hierarchies can coexist, where contradictions do not break the system, and where cross-domain linking is possible without forcing all contributors into one conceptual framework.
This is precisely why Wikidata is cautious about enforcing strict subclass/instance models and the the a Mereology Task Force is needed just to understand the consequences of many near-equivalent meanings of the “part of” relationship.
5.2.2 Formalisation
Advocates of data spaces sometimes describe them as “just connecting databases on an as-needed or as-permitted basis,” as if connection were a loose, informal network of API calls. But this is misleading. From a legal point of view, a database is either connected or not connected: if a system can dereference identifiers, look up metadata, or reuse statements, then the obligation to respect licenses, consent frameworks, provenance, and organisational constraints is triggered regardless of how lightly the connection is described.
The same precision applies on the semantic level. Our data sharing space does not avoid formal modelling. We represent our conceptual model in the Wikibase ontology, and this can be—and in practice must be—compiled into RDF and OWL axioms so that machines can interpret the classes, properties, role patterns, qualifiers, and constraints. We use property semantics, subclass hierarchies, equivalence mappings, reified statements, and alignment patterns that are fully compatible with OWL 2 DL or OWL 2 RL, depending on the use case.
Thus, “semantic mediation without semantic conformity” does not mean informality or the absence of a schema. It means something conceptually subtler:
The data-sharing space maintains a formally specified ontology—but one that does not require all participating institutions to conform to a single, domain-unifying conceptualisation.
The formalism exists at the mediation layer, not as a global schema that all domains must adopt.
A data space cannot function without a shared URI space, identity management, explicit class/property declarations, equivalence/near-equivalence mappings, domain/range expectations, inference patterns (even if limited), or consistent referential semantics. We just understand that we are making heavy trade offs for interoperability of systems, instead of serving one type of system’s internal workflows.
5.3 Future-Proofing
Future-proofing in a Data Sharing Space means designing systems so that the knowledge we curate today will still make sense — technically, legally, and conceptually — ten, twenty, or fifty years from now. Because our audience spans librarians, archivists, music-industry professionals, rights managers, researchers, and IT staff with very different technical backgrounds, the future-proofing strategy of the Open Music Observatory must be both technically rigorous and described in familiar terms.
To make this clearer, we describe future-proofing at four levels: the data model, the technology, the semantics, and the organisational workflows.
5.3.1 Future-proofing through graph architecture
Many library and industry IT systems are still based on relational databases (MySQL, Oracle, SQL Server) or on simple tables (Excel, Access). Increasingly, people have heard the word “NoSQL,” even if they haven’t used such systems directly, and associate it with flexibility and modernity.
A knowledge graph is a type of NoSQL system — but it is more than that. In a graph database:
- the schema is not a separate document living in an IT department’s folder;
- the schema is encoded in the data itself;
- every relationship (composer of, recorded at, part of, published by) is explicitly stored alongside the entities.
This means:
- the structure of the data can evolve without breaking old records;
- old data remains meaningful even after conceptual models change;
- future systems can read the RDF graph and rebuild the entire database without needing to know the original software.
Sadly, we often hear about cases when a developers passed away, or retired, and the latest database schema only existed in their heads. Graph databases connect the schema definition to every “table cell” forever. Often, our metadata repair work is re-discovering the not formalised schema of a legacy system.
For underfunded library IT environments, this is crucial. A “TTL dump” or “JSON-LD export” is not just a backup — it is the guarantee of a future database, often with a path to transitioning to a cheaper open-source loan or archive management software with the explicit help of documenting the data first. In a music label, such future proofing of Excel repertoires helps to automate catalogue transfer to a more affordable or better quality distributor.
5.3.2 Stabilising definitions through internationally defined standard vocabularies
When libraries, archives, or rights organisations use an SQL database, the meaning of a field often lives only inside that software. For example:
- “CreatorName” inside an old PHP/MySQL-based webshop might mean a composer, or a performer, or someone who once clicked the upload button.
- An “Author” field in a legacy library system may mix lyricists, arrangers, field collectors, annotators, and editors.
But DCTERMS, RDFS/OWL, and DDEX give clear, internationally defined meanings to these concepts.
This means:
- once your data is mapped to these standard vocabularies,
- future systems — even ones not invented yet — will know how to interpret it.
This is why DDEX is so powerful: even if a label used a 20-year-old MySQL database, once mapped to DDEX, the meaning becomes future-proof.
The same applies to:
- ISWC (work identifiers),
- ISRC (recordings),
- VIAF/ISNI (persons),
- RiC-O (archives),
- MARC relator codes (libraries).
Even if the technology changes, the semantics remain stable.
5.3.3 Future-proofing through translatability and multiple serialisations
In legacy systems, a database backup is often useless outside its native software. For example:
- An Access
.mdbfile from 2008. - A PHP webshop dumping
csvfiles in an ad-hoc format. - A FileMaker Pro database from a defunct project.
A graph database solves this because RDF data can be exported in many serialisations:
- Turtle (.ttl)
- JSON-LD
- RDF/XML
- N-Triples
- JSON
Each of these files is both human-readable and machine-readable, and any future graph system can rebuild the knowledge base from them — exactly the same way software can be rebuilt from source code. If you take a look at the description of the Structural Business Statistics (OpenMuse) dataset (Q600), it can be read as om:Q600.ttl or om:Q600.json
For cultural heritage preservation, this is vital:
If we preserve the RDF, we preserve the meaning — not just the data.
This is why OMO’s RDF exports act as both:
- a functional database backup, and
- a preservation format for future researchers, developers, and institutions.
5.3.4 Future services through institutional interoperability
Future-proofing is not only technical. It is also about making sure that libraries, archives, rights organisations, and small labels can move into the future without needing to throw away their old systems.
When a library aligns its catalogue with the SKCMDB (Slovak: hudobnadatabaza.sk) federated module of the Open Music Observatory:
- the library gains a modern semantic layer,
- the obsolete system gains a migration path,
- future library software can import the mapped RDF as its starting point.
This has already happened in Hungary and Slovakia: metadata that previously lived only inside ageing local catalogues has now been “semantic-lifted” into future-proof form.
The same applies to:
- music labels using old PHP/MySQL webshops,
- rights organisations with 1990s-era SQL systems,
- archives with hand-maintained Excel inventories,
- community collections with no database at all.
Once the data is mapped into the data sharing space, it becomes portable.
5.3.5 A concrete example: ALOADED, Livonian folk music, and DDEX
The ALOADED proof-of-concept demonstrates future-proofing in action, because it shows how archival cultural-heritage metadata, contemporary music-industry workflows, and emerging data-space standards can all meet in a single semantic pipeline.
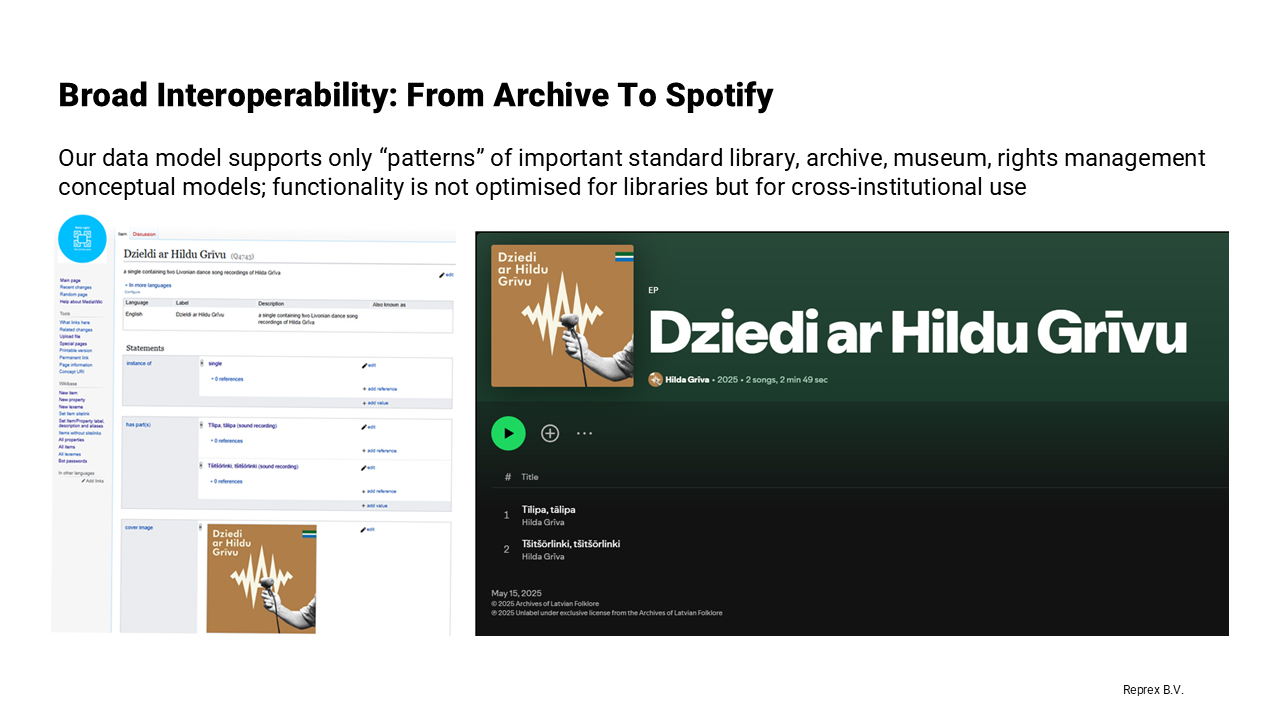
Our workflow proceeded in the following steps:
- We began with archival metadata about Livonian and Latvian folk music, including the tšitšōrlinki traditional dance song Q4169, with its associated field notes, handwritten scores, and contextual ethnographic information.
- This material included a corresponding archival field recording Q4166, originally catalogued in a traditional archival system that follows a very different descriptive paradigm.
- We then expressed this material using DDEX concepts Q4745, creating mappings between archival descriptions and DDEX’s contribution and release structures.
This transformation enabled several outcomes:
- the track could appear legally on Spotify
https://open.spotify.com/track/184iSrExWt2K9z7S4FvJYd - the musical score and the archival recording became findable on Garamantas.lv and Europeana
- creators and contributors could be credited transparently and correctly
- rights metadata could be clearly documented
- and the entire pipeline resulted in a FAIR, future-proof transformation of cultural heritage into a living, usable service
We describe this workflow in more detail in A Feasibility Study With Two Datasets on the Application of the Early Stage HDTO Ontology in Practice (Antal 2025a). There, we explore how early HDTO (Heritage Digital Twin Ontology) structures can support the future Europeana Data Space and the European Collaborative Cloud for Cultural Heritage, including creating digital-twin representations of cultural objects that:
have a non-commercial mechanical licence for scientific MIR processing
and a commercial streaming-safe version (e.g., Spotify) without download or AI-training permissions
This demonstrates how one song can travel through different rights regimes and different infrastructures — all mediated through a coherent semantic layer.
This is not only a proof-of-concept for technical interoperability. It also illustrates how a shared observatory infrastructure can enable the circulation of culturally vital but economically marginal repertoires.
The Livonian ethnolinguistic community is critically endangered. Making their vocal music available in modern channels is essential for revitalisation, language learning, and community visibility. Without the shared services of the Open Music Observatory, distributing such high-cultural-value but low-market-value repertoires would be practically impossible.
A listener can now:
- legally stream a piece of folk music (Spotify, Apple Music Classical, Deezer);
- then borrow or download the score from a library or from Garamantas.lv;
- a researcher can analyse the non-commercially licensed version using MIR tools;
- and anyone can explore the archival recording, contextual notes, and documentation connected to it.
This is future-proof music librarianship — linking listening, learning, research, and cultural memory.
One of our future development tasks is to model rights, permissions, obligations, and prohibitions directly inside the Observatory knowledge graph. We outline this in Wikibase as a Data Sharing Space: Connecting Rights, Communities, and GLAM through Federated Infrastructures (Wikidata Conference 2025) (Antal 2025b).
The EIF defines layered interoperability (legal, organisational, semantic, technical) (European Commission 2017a). The European Strategy for Data frames subsidiarity as compatible with federation (European Commission 2020). BDVA and the Federation Working Group emphasise that interoperability frameworks are needed to operationalise federation (BDVA/DAIRO 2023; BDVA/DAIRO Federation Working Group 2023).↩︎