4 AI that Works for Music, Not Against It
Most AI projects fail because they chase hype. MIT’s Project NANDA found that 95% of enterprise initiatives with generative AI delivered no measurable value. Budgets were spent on flashy pilots in sales or marketing, while the real potential — reducing back-office costs, prolonging the life of legacy systems, and avoiding constant IT churn — was overlooked.
Our approach is different. We do not see AI as “for its own sake.” Instead, we treat it as a way to reduce IT churn, keep legacy systems alive longer, and cut both capital and operating expenses. Where once every new regulation, distributor change, or catalogue migration required costly upgrades, curative AI can patch outputs from existing software, extend the lifespan of old systems, and make them interoperable with new ones. Shared infrastructures make this practical for micro-enterprises, NGOs, and collective management organisations (CMOs), who could never maintain such capacity in-house.
The European Parliament’s resolution on the music streaming market warns of the risks that AI-generated content poses for discoverability, attribution, and fair remuneration if metadata remains incomplete or unreliable. At the same time, the Music Ecosystem 2025 study highlights that AI will be both a disruption and an opportunity: while it can overwhelm systems with synthetic material, it also offers tools to automate documentation, reduce costs, and strengthen evidence-based policymaking (Music Moves Europe 2024, 23–24).
Artificial intelligence is therefore central to the future of Europe’s music ecosystem. On one hand, it threatens to exacerbate existing inequalities by concentrating technological advantages in platforms and major rights holders. On the other, it can repair, enrich, and automate processes that are otherwise prohibitively costly for small actors.
The problem in Europe is therefore not the absence of AI technologies, but the absence of shared infrastructures that allow smaller actors to benefit from them. The challenge is not whether such AI will be used, but whether its benefits will be distributed fairly across the ecosystem. The European policy framework already implies this conclusion, even if it is not always stated explicitly. The AI Act, the Data Governance Act, and the broader European data space strategy all assume that trustworthy AI depends on access to high-quality, well-governed data that remains under distributed control rather than centralised ownership. In practice, this means that AI systems can only be lawful, auditable, and fair if they operate on interoperable, provenance-rich, and rights-aware datasets.
In the music sector, these conditions are currently not met. Rights metadata is fragmented, identifiers are inconsistently applied, and provenance chains are incomplete. As a result, even well-regulated AI systems cannot reliably ensure attribution, fair remuneration, or compliance with copyright and data protection rules. The bottleneck is therefore not algorithmic capability, but infrastructure and governance.
This has a direct implication: improving AI outcomes in music is not primarily a matter of regulating models, but of building shared, federated data infrastructures that make trustworthy metadata available across the ecosystem. Without such infrastructures, AI regulation remains largely theoretical, because the underlying data conditions required for compliance and fairness are absent.

The Culture Compass for Europe recognises both the opportunities and risks of AI for cultural and creative sectors. Music illustrates these risks earlier and more visibly than most sectors, because AI systems rely heavily on large-scale music datasets for training, recommendation, and generation. In this context, trustworthy provenance and rights-aware metadata are not optional safeguards, but prerequisites for lawful and ethical AI deployment.
The use, development and governance of artificial intelligence (AI) systems should foster human creativity through a fair human-centric and rights-based approach. It should: respect cultural rights, accessibility, inclusivity and cultural diversity; develop and promote discoverability of European, national and local content; foster competitiveness; counter digital divides; and foster digital inclusion. We commit to:
• Promoting human creation and European cultural and linguistic digital sovereignty, and addressing ethical risks of biases and cultural homogenisation.
• Protecting intellectual property rights, by addressing the impacts of AI on creators’ remuneration, while embracing innovation.
• Monitoring and mitigating the impact of AI on jobs, as well as supporting the cultural and creative sectors and industries adapt to technological change and acquire digital skills.
• Fostering the use of AI as a tool to support cultural and creative professionals, and enabling the cultural and creative sectors and industries to harness the opportunities offered by these technologies.Draft Joint Declaration “Europe for Culture — Culture for Europe” (European Parliament, Council of the European Union, and European Commission 2025)
European policy provides evolving guidance on this balancing act. The Ethics Guidelines for Trustworthy AI underline that AI must be lawful, ethical, and robust throughout its lifecycle (Commission, Directorate-General for Communications Networks, and Technology 2019). The Getting the Future Right report by the Fundamental Rights Agency stresses the need to align AI with fundamental rights, especially where vulnerable groups and cultural participation are concerned (European Union Agency for Fundamental Rights 2020). Most recently, the AI Act enshrines a risk-based regulatory framework, defining obligations for providers and deployers of AI systems while reaffirming the principles of subsidiarity and proportionality in EU digital policy (European Parliament and Council 2024).
Our own engagement with these issues began with the Listen Local feasibility study in 2020. By experimenting with the Spotify API, we discovered that Slovak users were rarely recommended Slovak music — not because Spotify was at fault, but because the data about local repertoire was sparse. Spotify’s open API was, in fact, uniquely transparent compared to competitors, and it enabled us to see a larger policy problem: without structured, machine-readable knowledge of diverse repertoires, algorithms cannot deliver fair outcomes. This lesson has guided our work ever since: improving metadata and interoperability is the first step to better AI governance, because AI systems ultimately rely on the same copyright infrastructures — identifiers, provenance chains, and lifecycle metadata — described in the CITF framework and implemented through the Open Music Observatory. 1.
During the Listen Local feasibility study (2020), we experimented with the Spotify API and found that Slovak listeners were rarely recommended Slovak music. This was not Spotify’s fault. In fact, Spotify’s open API and conceptual documentation gave us more insight than any competing platform (Deezer and Apple never even replied to our requests).
That transparency revealed a deeper policy issue: without structured, machine-readable metadata on diverse repertoires, even the most advanced recommender systems cannot deliver fair results. This insight shaped the rest of our work — showing that better outcomes depend not on blaming algorithms, but on supplying them with the right knowledge.
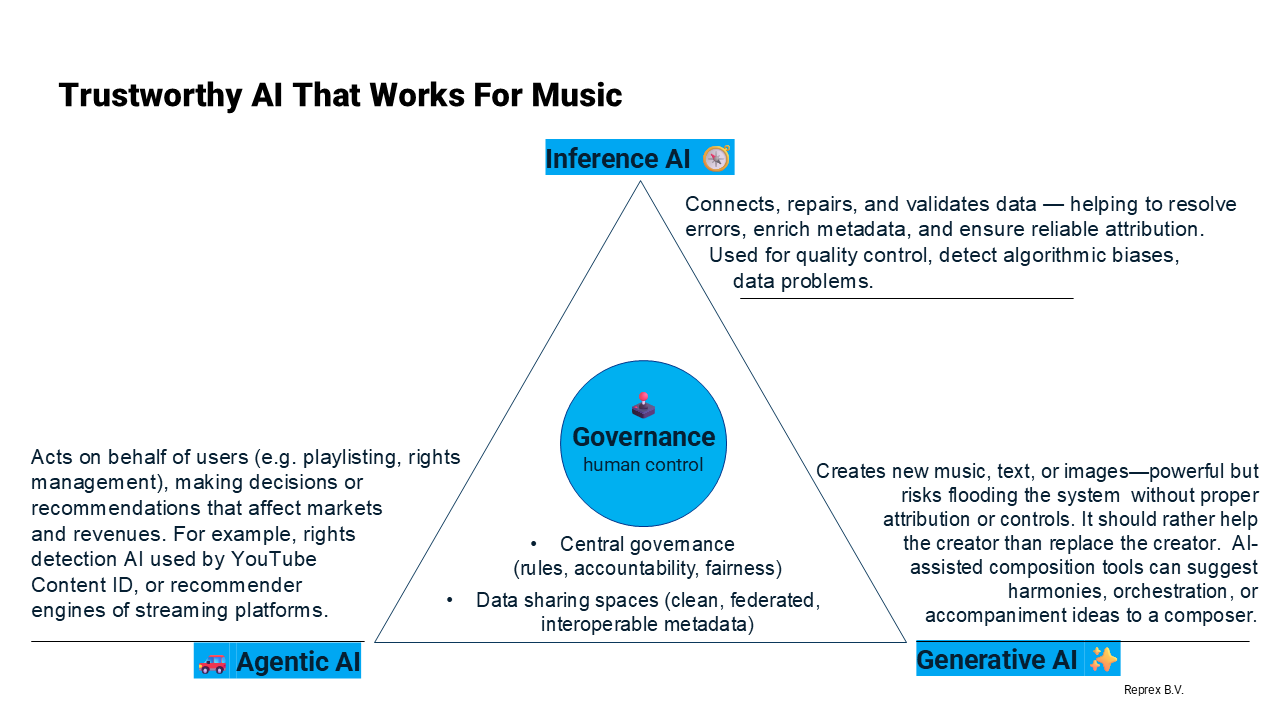
Today, the same dynamics are playing out across the ecosystem. Agentic AI powers recommender systems and rights management tools; Generative AI is spreading rapidly, raising fears for the economic basis of music; and Inference AI offers a path to guardrails, cross-checking recommendations against cultural policies (such as local content quotas) or verifying generative outputs against copyright and attribution rules. Our proposal is triangular: agentic, generative, and inference AI should complement and, when necessary, correct each other — always with the human in ultimate control.
Generative AI is increasingly perceived as threatening the livelihoods and existing rights of rightsholders. The Open Music Europe consortium did not study generative AI in-depth; our initial focus was on untrustworthy use of agentic AI2. We want to highlight again our analysis from Chapter 2 that metadata is never neutral.
Against this backdrop, the Observatory proposes AI not as a substitute for human creativity or governance, but as a shared utility: a way to pool curative, agentic, and generative services within a federated infrastructure. This ensures that SMEs, non-profits, and community archives gain access to trustworthy AI capacities, reducing costs and risks while preserving diversity and accountability in the European music ecosystem.
4.1 Discussion
4.1.1 Where the AI value pools are — and why music businesses struggle to access them
Management research increasingly describes the economic benefits of artificial intelligence as “AI value pools”: areas of business activity where AI can measurably increase revenues, reduce costs, or improve capital efficiency. In music, these value pools already exist — but they are unevenly captured. Platforms and large intermediaries have been able to exploit them for more than a decade, while most music businesses lack the scale, data infrastructure, or technical staff required to participate.
Shared infrastructures such as the Open Music Observatory are therefore not simply research tools but mechanisms for unlocking these AI value pools for the wider music ecosystem.
Most AI value pools are captured by platforms
Music businesses operate in value chains where platforms and large intermediaries already use agentic, generative, and even inference AI. Most platforms already rely on agentic workflows (matching, recognition, playlisting, claim resolution). These actors capture most of the economic value, while smaller publishers, labels, and managers often remain outside the AI value pools that shape discoverability, rights management, and revenue flows.The main AI value pools affect the music business bottom line.
In practice, the main AI value pools in music appear in four areas: operating costs, capital costs, working capital, and sales performance.
Operating costs (OPEX): Most European music is released by self-publishers or very small labels who cannot afford dedicated staff for documentation or accounting. They save costs by using Excel or freelance accountants, but per unit this is very expensive and leads to poor metadata. As a result, their works perform badly on agentic platforms where poor documentation means poor sales. AI could sharply reduce documentation and claims costs — but accessing these efficiencies requires infrastructure that most small actors cannot build alone.
Capital costs (CAPEX): Investing in proper IT or ERP systems is rarely viable at small scale. A system that pays off when managing a million works is wasteful when managing 3,000. Curative AI can extend the life of outdated IT systems and reduce the need for costly replacements, unlocking a major AI value pool in capital efficiency.
Working capital: Many rights holders experience late or missing royalty payouts, even for well-known artists, because the cost of claiming is high compared to the low value of claims. This ties up cash between payment periods. AI could accelerate claims processing and improve matching, unlocking a value pool in working-capital efficiency by reducing delays in royalty flows.
Sales: While dedicated “sales AI” projects are often prone to failure, in music most transactions already run through agentic AI on platforms like Spotify, YouTube, TikTok, and Apple Music. Simply providing these agents with better documented music can improve sales outcomes, allowing music businesses to participate in AI-driven discovery without building their own AI sales systems.
Generative AI is only one part of the AI value equation.
Public debate often focuses on generative AI flooding the market with unlimited non-copyrighted music, which can devalue existing repertoires. This is a real issue, but it is not the only one. Agentic AI in distribution platforms has been shaping the market for at least 14 years, determining who gets discovered, listened to, and paid — long before generative AI became a concern3.The talent gap prevents access to AI value pools.
Recruiting and integrating digital expertise is difficult across industries, but especially in music where most enterprises are micro-enterprises. A Chief Data Officer (CDO) is often recommended, yet unrealistic for most publishers, labels, or agencies. Even Fortune 500 companies — far larger than Europe’s 50,000 “large” enterprises — report persistent difficulties in filling CDO and AI leadership roles. With 23 million SMEs in Europe, and several hundred thousand music entities, usually with less than 2 people in full-time positions, this AI and data talent shortage cannot be solved on an individual business level4.
4.1.2 European regulation that misses the point
Europe prides itself on having some of the world’s strictest AI rules. Compared to the United States and China, the EU has adopted a risk-based framework in the AI Act, with strong obligations for high-risk systems (such as self-driving cars) and lighter rules for low-risk ones. But this framework is poorly suited to music.
Music was classified as “low-risk” on the assumption that nobody is harmed by being offered a bad song. This framing ignores how agentic AI governs the marketplace itself. If recommendation systems consistently fail to show music created by women, small nations, or minorities, they devalue those repertoires to zero by depriving them of discoverability. Copyright value is based on the present value of expected royalty flows; if works are never recommended, those flows vanish, and with them the rights protected under EU law and international treaties.
In other words: Europe regulates AI strictly where physical safety is at stake, but does not protect cultural diversity, women’s authorship, or the economic rights of creators. What is framed as “low-risk” can in practice be systemically high-risk for the music ecosystem. This problem is then reflected in the actual design of commercial or institutional AI systems.
This categorisation becomes even more problematic with the rise of large language models (LLMs) and their applications like ChatGPT, Gemini, Llama. The “Human Artistry Campaign” was initiated by a coalition of 150+ organisations, including major music industry bodies (IFPI, RIAA, BPI) and artist representative groups (AIM, Featured Artists Coalition, Impala), establishing a collaborative effort to advocate for responsible AI development within the creative sector.
However, recent research questions if the EU’s AI Act is even practically applicable as a legal framework to Generative AI. The Act’s risk-based categorisation may struggle to capture the emergent behaviour of LLMs and their potential for misuse, and it is highly questionable that human oversight or human control is possible with LLM alone5.
Last, but not least, we want to highlight that efforts at metadata repair and publication — as we propose in earlier chapters — also increase the risk of generative AI misuse.
A prompt like create me an ABBA-like disco hit is likely to combine:
- Core musical learning from audio/MIDI (raising clear copyright and GDPR risks), and
- Metadata signals that guide the model’s interpretation.
Core musical learning (from audio/MIDI):
From training on ABBA’s catalogue (and related artists), a model learns to reproduce:
- Harmony → diatonic progressions (e.g. I–V–vi–IV), bright major keys.
- Melody → catchy, stepwise motifs (e.g. Mamma Mia hooks).
- Rhythm & texture → steady 4/4 grooves, piano/guitar foundations, layered vocals.
- Structure → verse–chorus–bridge arcs with memorable refrains.
- Production cues → lush vocal overdubs, polished pop arrangements, disco influences.
How metadata sharpens the imitation:
- Artist metadata (“ABBA”) → links to Swedish pop, Eurovision history, chart success. Tags like “Europop,” “disco-pop,” “vocal harmony group” cue specific stylistic markers. Models may also trace producers and collaborators to expand training.
- Genre/award metadata (“disco-pop hit”) → narrows toward 1970s–80s tropes: syncopated basslines, string pads, tambourine.
- Chart/award metadata → biases output toward catchy, chorus-driven songs resembling global hits.
The paradox:
- Metadata repair makes ABBA’s legacy more discoverable across platforms (archives, streaming, Wikidata, Wikipedia).
- But richer metadata also helps AI pinpoint and reproduce their exact style, making prompts like “ABBA-style Eurovision anthem” feasible.
Metadata empowers and exposes: it restores visibility for heritage and repertoire, but also creates new pathways for substitution by generative AI.
For this reason, metadata governance is a policy concern, not just a technical task6.
4.1.3 Policy issues at the intersection of AI, copyright, and GDPR
AI in music does not operate in a legal vacuum. It interacts with existing European law on intellectual property, author’s rights, moral rights, and data protection. In practice, this creates tensions and unresolved policy gaps that directly undermine cultural policy goals. This governance problem builds directly on the interoperability failures described in Section 3.1.3.
- Attribution vs GDPR.
The Treaty on the Functioning of the European Union enshrines protection of intellectual property. European copyright law gives authors moral rights, including attribution. Yet GDPR may prohibit storing or publishing the same identifying data needed to respect these rights. In the absence of jurisprudence from the Court of Justice of the EU or guidance from competent data protection authorities, actors who try to give proper attribution risk GDPR penalties. This legal uncertainty has direct implications for AI:- If attribution is blocked, it becomes impossible to test whether AI systems treat authors fairly.
- More broadly, GDPR makes it difficult to safeguard against algorithmic discrimination if information on gender, nationality, or other attributes cannot legally be used7, and the current announced revision of GDPR by the Commission is the best moment to address this problem.
- Local content protection gaps.
In broadcasting, local content quotas were established in line with WTO rules to safeguard cultural diversity (e.g. Slovak private radios playing at least 25% Slovak music). Similar obligations now exist in audiovisual streaming. But in music streaming there are no binding European diversity or local content rules. This creates two problems:- AI-driven distribution platforms can crowd out local repertoire with global catalogues, depriving smaller nations of audiences.
- Even where voluntary quotas exist, compliance depends on knowing the origin of repertoire. If we cannot know whether a work is Slovak, French, or by a young author, quotas or diversity targets cannot be implemented.
- Voluntary compliance is impractical. Current practice relies on voluntary measures by radio editors, festival curators, or platform users to include local or diverse content. But without accessible data, this becomes unworkable. Our own experiments with GDPR balancing tests and opt-ins show the futility of this approach. Fewer than 1% of artists responded to requests to consent to attribution data — even prominent Slovak artists, puzzled at being asked to consent to rights they already legally hold.
In short, AI cannot be made trustworthy for music without resolving these legislative and policy blocks. The AI Act currently misplaces risk, treating music as “low-risk” while ignoring systemic harms. GDPR, in practice, blocks data use that would enable fairness testing. And the absence of local content rules in streaming removes a cornerstone of cultural policy. AI in music will remain misaligned with European policy goals unless these conflicts are addressed.
4.1.4 AI design without awareness of limits
AI systems are not usually designed with an awareness of their own conceptual limits.
Agentic AI systems (recommenders, playlist builders, rights-management bots) operate without recognising the biases or incompleteness of the datasets they learn from. Because European legislation currently treats most uses of AI in music as “low risk”, there are few regulatory expectations to address this problem.
Generative AI produces synthetic material without constraints, and its training processes seldom acknowledge gaps or skew in the underlying data. This problem touches upon various issues that we discussed earlier in this paper: author’s rights and performer rights are assigned to natural persons (and their heirs), as well as sometimes producer’s rights, too. GDPR currently appears to conflict both with designing safer AI systems and with providing proper attribution without legal risk to creators of protected work. We could technically guardrail generative AI to not produce plagiarism, but not without giving it access to whose work is forbidden.
Even Inference AI, which is designed to reason from formal rules, can miss the point: ontological relativity and incompleteness are structural limits and not optional refinements. We discussed in the Chapter 2, and just as well as database designers must be aware that that no ontology or schema is ever complete, AI engineers must realise that they train algorithms that cannot capture all perspectives. Without this awareness, AI will silently reproduce exclusions — whether of women, minorities, or smaller repertoires — while appearing “intelligent.”
This is a design issue: the guardrails must be built in from the start, not bolted on afterwards. We see a lot of promise in building Inference AI tools, perhaps in a public-private partnership, that can actually provide help for human-in-control principles for the use of agentic and generative AI.
4.1.5 Unfreezing frozen assets
Many music assets remain “frozen” because their documentation costs exceed their current commercial value. This applies to non-commercial repertoires, small-label releases, and culturally valuable but low-market recordings. Without affordable workflows, these works cannot enter modern distribution systems, regardless of their cultural or artistic significance.
The Unlabel pilot illustrates this problem: by treating catalogue transfers and documentation as high-cost, high-friction processes, valuable repertoires remain locked away. AI-assisted metadata repair and DDEX-compliant catalogue transfer workflows provide a pathway to lower costs and bring neglected repertoires back into circulation.
Example: Old SQL Database in a Cultural Institution
A label or archive has a recording stored in a 20–30 year-old SQL database, built on a schema that was never fully documented. The system’s author is retired (or no longer alive).
The institution wants to re-release the recording, but to distribute it today, the metadata must be expressed in DDEX Catalogue Transfer messages — a completely different schema, designed decades later.
Curative AI
Acts at the system level: it can “read” the old database structure, infer undocumented field meanings, and patch outputs so the legacy database can still talk to modern pipelines.
Instead of rebuilding or migrating the old database (expensive, risky), curative AI extends its lifespan by making its outputs usable.
Reparative AI
Acts at the metadata/epistemic level: it can detect inconsistencies or missing fields (e.g., composer names stored in free-text notes, titles in mixed languages) and reformat or enrich them into structured DDEX-compliant fields.
This not only enables distribution but also restores visibility for works that might otherwise remain trapped in inaccessible formats.
The policy point
Without curative/reparative AI, such recordings risk becoming “frozen assets”: legally owned but practically undistributable because the metadata cannot be transformed.
By investing in these AI uses, Europe can preserve access to cultural heritage, reduce IT churn, and ensure that both heritage archives and independent labels can connect to modern digital value chains.
Unlike U.S.-style copyright, Europe’s author’s rights regime contains a moral component. Authors (and, for a period, their heirs) retain certain rights over how their works are used, even after economic rights expire. This recognises that works are part of a creator’s moral and cultural heritage, not only economic assets. Various legal norms, for example local content rules, have historically provided tools to national or linguistic communities to provide some guardrails to the use of their shared heritage, even this means community stewardship and not inheritance in legal terms.
Metadata repair and publication strengthen visibility, but also create risks that generative AI will use these works in ways that undermine moral rights, where heirs object to uses they see as distorting or trivialising an author’s legacy and community stewardship norms, where groups perceive their folk or minority heritage as being misappropriated, even when no legal infringement occurs.
While we do not identify these challenges at this point as similarly actionable public policy challenges as the problems of GDPR and the creation of trustworthy music AI, regulators do face political risk if ethical expectations of communities around cultural stewardship are not addressed. Even if no author’s rights or other legal norms are breached, the ability to create “fake” Livonian, Latvian or Basque folk songs may strongly conflict with the expectation of communities on the ethical use of AI.
4.1.6 AI support for investment into new repertoire assets
While generative AI that disregards human repertoires can undermine cultural value, AI also has constructive roles. Just as photographers benefit from embedded AI in tools like Photoshop or GIMP, musicians and producers can use AI to reduce the costs of composition, recording, and documentation. In practice, this means that creating new works and registering them with identifiers can become less burdensome and more accessible.
This perspective aligns with the European Parliament’s call for “metadata from birth” (European Parliament 2024), but it goes further. AI can not only generate metadata automatically at the moment of creation, but also support sound recording, scoring, and archiving processes directly, ensuring that new assets enter circulation with complete, interoperable metadata.
4.2 Policy Proposals: Aligning AI with Governance and Value Creation
Generative, agentic, and inference AI are now woven into the global creative economy. But value is not created by algorithms alone — it comes from governance, curated data, and institutions that ensure trust. Policy interventions are needed on three levels: EU, industry, and organisational.
Our focus is the metadata and data needs of the music ecosystem — labels, distributors, publishers, managers, CMOs, archives — not the creative act of composing music itself.
4.2.1 EU-Level Policy: Compass and Guardrails
- Embed cultural sectors in the EU AI Act & Data Spaces so music and cultural industries are not treated as “low risk.”
- Subsidise shared AI utilities for identifier reconciliation, metadata repair, and fraud/plagiarism detection.
- Adopt “metadata from birth” principles: embed ISNI/ISWC/ISRC identifiers at the point of creation.
- Tax incentives for onboarding frozen assets, supporting digitisation and enrichment of under-documented catalogues.
- Resolve attribution vs GDPR conflicts through legal clarification or jurisprudence, enabling fairness testing and copyright compliance.
4.2.2 Industry-Level Policy: Standards and Collaboration
- Codes of conduct for AI in music, modelled on GDPR codes.
- Identifier crosswalks across ISRC, ISWC, ISNI, VIAF, etc.
- Federated AI services for claims, reconciliation, multilingual enrichment.
- Training and reskilling to close the AI/data talent gap.
- Working capital optimisation through AI-assisted claims and faster distributions.
These principles do not stand in isolation: they echo and extend ongoing work such as the Responsible AI Music framework, ensuring that sector-specific practices in Europe are consistent with emerging international standards.8
4.2.3 Organisational-Level Policy: Playbooks for CMOs, Publishers, Archives
- Embed AI in workflows so metadata is generated and validated during creation/distribution.
- Capture once, reuse many times, reducing redundant re-entry.
- Invest in knowledge capital, not IT churn (ontologies, vocabularies, multilingual enrichment).
- Subscribe to shared AI utilities instead of bespoke in-house builds.
- Develop internal AI governance — even small actors can appoint an “AI steward.”
4.2.4 Curative AI and Reparative AI as a Remediation Solution
While data spaces establish rules for new data flows, they do not address the legacy backlog of poorly formatted or incomplete open data. Here, curative AI provides a complementary solution.
AI-assisted services can detect duplicates, infer missing identifiers, reconcile heterogeneous formats, and enrich metadata with multilingual descriptions. In effect, they transform datasets that are legally open but practically unusable into resources that can circulate across the ecosystem.
Curative AI as regeneration, not replacement

The Ise Grand Shrine in Japan has been in continuous use for 1,600 years — not because its wooden beams never rotted, but because the knowledge of renewal was embedded and transmitted across generations. The true asset was the embedded know-how of regeneration, not any single plank of wood.
Curative AI can play the same role in the digital domain:
- Extend the life of legacy systems by fixing patchy outputs from old ERPs, catalogues, or distributor software.
- Preserve the methods of repair: how to reconcile corrupted records, reshape data for new systems, and upgrade databases while remaining compatible with older formats.
- Transform investment logic: instead of constant capex for new IT systems, shared data infrastructures with curative AI reduce costs, smooth opex, and deliver future-proof and past-proof services.
Our pilots — such as Unlabel and SKCMDb — show that new value can be created without additional IT investment or system upgrades by the participating companies, libraries, and rights management agencies.
Thus, governance and remediation are two sides of the same coin:
- Data sharing spaces ensure that new data is created in interoperable ways.
- Curative AI repairs the inherited stock of legacy and low-quality datasets.
Together, they close the gap between the right of reuse (granted by the Open Data Directive) and the means of reuse required for music, culture, and AI-driven innovation.
4.2.5 Lowering Documentation Barriers
We propose to adapt Unlabel’s approach as a model for unfreezing frozen assets. By leveraging AI-assisted metadata repair and DDEX-compliant catalogue transfer workflows, documentation costs can be reduced enough to enable non-profits, small labels, and community archives to register and redistribute neglected repertoires. Public support should subsidise onboarding costs, create standardised pipelines, and incentivise low-friction reuse of metadata across systems.
4.2.6 Observatory: European = Open
When we call for a European Music Observatory, the adjective “European” should not be read as a cultural filter that limits scope to European repertoires. Music is, and always has been, global. The task of the Observatory is not to create an insular archive of “European music,” but to build a governance and data architecture rooted in European values:
- Data sovereignty — ensuring that creators, communities, and institutions have meaningful control over how their metadata and works are represented.
- Subsidiarity — solutions should be built at the lowest effective level, allowing national archives, collective management organisations, and industry actors to contribute without being absorbed into a single monolith.
- Inclusiveness — minority repertoires, independent artists, and small markets must be equally visible alongside the global catalogues of multinational platforms. Our Finno-Ugric case studies show how fragile metadata can be repaired without erasing community perspectives — a model that must be embedded at Observatory scale9.
This is why we chose the name Open Music Observatory (OMO). Even if the policy framework ultimately labels it the “European Music Observatory,” the essential principle must remain openness — of infrastructure, of governance, and of participation. The Observatory should be a federated knowledge space, not a centralised database.
Europe has an opportunity to take a step that resonates beyond its borders. The U.S. Mechanical Licensing Collective (MILC) demonstrated how a single initiative could set standards and ripple globally. An Open Music Observatory, grounded in European governance but open to the world, could play a similar role — aligning sovereignty with interoperability, and showing how collective data architectures can provide guardrails for AI in a truly global music ecosystem.
4.2.7 The Open Music Observatory as a Collective Guardrail
AI will only create sustainable value for music when governance, interoperability, and human capital are aligned. Building effective guardrails for agentic and generative AI cannot be achieved by individual firms or even national markets alone.
At the business level, most organisations lack the scale, incentives, or expertise to monitor how AI systems use metadata and cultural datasets. At the industry level, cooperation is necessary but often fragmented by competing commercial interests. These structural limitations make coordinated infrastructure essential.
This is where the European Union can play a decisive role: by aligning existing investments in Europeana, the European Collaborative Cloud for Cultural Heritage (ECCCH), and emerging data sharing spaces, and anchoring these initiatives in a federated Open Music Observatory built around Wikibase-compatible knowledge graphs. In such an architecture, metadata repair and publication do not only improve attribution and interoperability; they also feed into collective data infrastructures that can function as guardrails for AI systems.
In 2024–25, Wikimedia Deutschland, together with Jina.AI and DataStax, launched the Wikidata Embedding Project, introducing vector-based semantic search to Wikidata. By combining the multilingual Wikidata knowledge graph with modern embedding models, the project enables context-aware retrieval for AI systems while grounding outputs in a public, verifiable knowledge base.
This approach greatly improves the usability of knowledge graphs, which remain unfamiliar to many users of music databases. A similar architecture is already being demonstrated and continuously improved in the Open Music Observatory (https://openmusicobservatory.eu/).
Why this matters for music policy
The project demonstrates that guardrails for generative AI can be built on open, community-governed knowledge graphs rather than proprietary black-box systems. By grounding AI outputs in structured, verifiable data, such architectures can:
- reduce hallucinations through retrieval from trusted sources,
- combat misinformation through transparent references, and
- amplify underrepresented knowledge by balancing global visibility.
Implications for the Open Music Observatory
By adopting Wikibase-compatible knowledge graphs and established ontological patterns, the Open Music Observatory can provide similar safeguards for music data. In this model, metadata repair and publication become part of a collective data architecture that strengthens attribution, transparency, and accountability in AI systems.
Within this framework, the Open Music Observatory provides:
- Compass and coordination at the EU level,
- Standards and shared utilities through industry cooperation, and
- Flexible governance and operational playbooks for organisations.
In such an architecture, AI becomes a tool for continuous renewal of cultural infrastructure: prolonging the life of legacy systems, unfreezing frozen cultural assets, and supporting both heritage and new repertoires, while embedding safeguards against substitution and misappropriation directly into the data infrastructure of Europe’s music ecosystem.
The CITF report stresses that AI-related obligations cannot be met unless rights metadata, identifiers, and provenance chains are trustworthy and repairable, and that fragmented RMI makes it impossible to ensure fair attribution or compliant AI outputs [Partanen et al. (2025), pp20; p31].↩︎
The term agentic AI refers to AI systems that operate with some degree of autonomy and goal-directed behaviour, and it is not present in the language of the European AI Act. In academic and technical contexts, this covers agent-based frameworks (where AI systems act in an environment, plan, and adapt), which can be applied either to generative models (e.g. creating music or images) or to workflow automation (e.g. metadata correction, licensing negotiation). By contrast, recommender systems such as collaborative filtering — widely used in music platforms — are not agentic, since they do not act independently of user input. We retain the shorthand “agentic AI” in this Green Paper for accessibility, but recognise that multiple sub-classes of AI systems are involved.↩︎
Surveys and management research confirm these patterns. PwC’s Global CEO Survey shows how quickly generative AI rose from a marginal issue in 2023 to a central boardroom concern by 2024–25, though most executives expressed only “bounded optimism” (PwC 2024). Bloomberg and BCG’s CEO Radar tracked quarterly earnings calls in 2025, reporting a 100% increase in references to AI and machine learning, but also rising caution about productivity claims (Bloomberg and Boston Consulting Group 2025). MIT’s Project NANDA concluded in August 2025 that 95% of enterprise generative AI initiatives failed to deliver measurable value, with back-office automation offering the clearest returns (MIT Sloan School of Management 2025). These findings mirror evidence from talent studies: Gartner’s CDO Survey reports persistent shortages in chief data officer and AI leadership roles, even among Fortune 500 companies (Gartner, Inc. 2024), while PwC’s Digital IQ survey highlights the difficulties of capturing ROI on digital transformation and AI investments (PwC 2023).↩︎
According to Eurostat’s Culture statistics — 2023 edition, cultural and creative industry (CCI) enterprises in the EU are overwhelmingly micro-enterprises. More than 95% employ fewer than 10 people, and the average enterprise size across the sector is below two employees (Eurostat 2023). This structural feature explains why most music publishers, labels, and agencies lack in-house IT, accounting, documentation, or HR functions — and why recruiting specialised AI or data talent is unrealistic without shared infrastructures.↩︎
Towards Responsible AI Music: an Investigation of Trustworthy Features for Creative Systems is an excellent review of the theoretical or practical applicability of the EU’s trustworthy AI paradigm for generative AI (Berardinis et al. 2025). For more information on the Human Artistry Campaign, see https://www.humanartistrycampaign.com/.↩︎
CITF frames this as a core AI-era requirement. It argues that lifecycle-based provenance and machine-readable RMI are essential for assessing lawful uses in training and generation, and that without interoperable identifiers, neither attribution nor AI governance can scale [Partanen et al. (2025), pp28–33; pp101–102]. This tension is also recognised in recent policy research.↩︎
CITF identifies this same contradiction. It notes that attribution data is simultaneously necessary for copyright, required for RMI, and treated as personal data under GDPR, creating legal uncertainty that directly undermines AI governance, lifecycle compliance, and fairness testing (Partanen et al. 2025, pp12–18).↩︎
The Responsible AI Music framework (RAIM) sets out principles for transparency, fairness, sustainability, and accountability in the use of AI in music (Herremans, Sturm, et al. 2025). Several of the codes of conduct proposed here — such as clarity around data provenance, safeguards for attribution, and limits on exploitative recommendation practices — align closely with RAIM’s recommendations. Where RAIM defines broad principles, this Green Paper provides concrete mechanisms for their operationalisation within European music data spaces and observatories.↩︎
We have created the second federated module of the Open Music Observatory with contemporary popular and authentic folk music of European Finno-Ugric minorities who do not have a nation state. (Antal et al. 2025)↩︎